Microsoft Service Manager для ИТ подразделения. Часть 1. Инциденты и проблемыАвтор: Данил Динцис
Опубликовано: 01.03.2011
Источник: SoftKey.info
Называется программный продукт довольно длинно: Microsoft System Center Service Manager. Дело в том, что Майкрософт представляет на рынке не единичный продукт, а комплекс решений, направленных на управление информационной инфраструктурой компании. Единое название этого решения Service Center – Центр услуг, а Service Manager – это продукт, который позволяет организовать работу ИТ подразделения компании и его взаимодействие с внутренними пользователями.
Управление ИТ службой компании по принципу оказания услуг, так называемый ITSM – IT Service Management, зародился около 25 лет назад и получил чрезвычайно широкое распространение в последние лет 15 в мире и лет 7-8 в России. Базовые подходы изложены в библиотеке ITIL, однако, она достаточно абстрактна. И на практике обычно пользуются детальными методиками либо собственной проработки, либо известных на рынке компаний: Microsoft Operations Framework (MOF), HP IT Service Management Framework, COBIT, IBM Tivoli Framework. Но это организационные методики, для их практического воплощения необходимо использовать различные программные инструменты. И одним из таких программных средств, как раз и является Service Manager от Майкрософт.
Обычно построение сервисного подхода в работе ИТ службы начинается с организационного упорядочивания обработки заявок пользователей: инцидентов, разного рода запросов. Service Manager удачно реализует эту функцию, позволяю построить ранжированную по приоритетам систему управления инцидентами от подачи заявки на портале до формализованной процедуры ее закрытия. Посмотрим сначала, как происходит ранжирование инцидентов. В соответствии с рекомендациями ITIL, MOF приоритет инцидента определяется на основе «степени влияния» (Impact) и «срочности» (Urgency). При этом в Service Manager степень влияния может быть связана с классификационной категорией, т.е. с сервисом. В результате приоритет каждого конкретного инцидента выставляется автоматически. Это очень полезно, т.к. позволяет минимизировать разногласия по с бизнес-пользователями относительно времени и порядка отработки их заявки.
Сам перечень бизнес – сервисов может формироваться как автоматически, так и внесением вручную, что придает системе достаточную гибкость. Автоматически импорт сервисов производится через меню «Business Services» с использованием других приложений Microsoft: Active Directory, Configuration Manager, Operation Manager. Стоит отметить, что последние 2 приложения входят в состав System Center и органично взаимодействуют с Service Manager. Более того, эксплуатация SCSM без установленного SCOM (Operations Manager) лишает его существенной части функционала. Ручной ввод специализированных или комплексных сервисов можно выполнить в меню Business Services, используя группу по умолчанию “All Business Services” или создавая собственные логические подгруппы. Очень полезна функция привязки статей из базы знаний к сервисам или конкретным конфигурационным единицам, как показано в правом меню на рис.
Рассмотрим теперь полный жизненный цикл заявки (инцидента) в SCSM.
В соответствии с рекомендациями ITIL, MOF первым действием должна быть регистрация инцидента. SCSM дает несколько вариантов для регистрации:
Лично пользователем через форму на портале
Автоматически средствами Service Center Operation Manager (SCOM)
Оператором службы поддержки.
В каждом случае идентифицируется пользователь или группа пользователей, которые затронуты инцидентом. Далее проводится классификация: привязка к сервису и на ее основе определение приоритета. Приоритет в SCSM устанавливается на основе категории сервиса, срочности и степени влияния на бизнес-процессы. Эти параметры можно предустановить, например, для типовых инцидентов. Таким образом, минимизируются возможные противоречия о назначении приоритета (см. рис.1)
 | | Основное окно карточки инцидента |
Инцидент назначается на ответственного сотрудника, причем при эскалации на другого сотрудника ведется история действий в отдельной вкладке в карточке инцидента. Это стандартная практика для систем управления ИТ инфраструктурой. Она позволяет четко определять, кто и когда устранял неполадки, сколько затрачено времени, и какие потребовались ресурсы.
В итоге формируется полная сводка по каждому инциденту: кто и сколько занимался исправлением; какие сервисы, люди, оборудование было затронуто. Ведется учет связанных инцидентов, т.е. сбоев, которые в свою очередь вызваны данным инцидентом или каким-то иным образом с ним связаны, например, общей корневой проблемой. Наконец, по результатам подвязываются статьи из базы знаний. Это необходимо для более быстрого и корректного устранения подобных неполадок в будущем.
 | | База знаний для инцидентов |
Разумеется, контролировать каждый отдельно взятый инцидент – задача слишком емкая и потому непроизводительная. Основной контроль производится статистически за период. Например, за рабочий день. По умолчанию в SCSM есть отчеты: по всем инцидентам; по открытым; по просроченным. Как правило, при внедрении создаются собственные отчеты на основе встроенных фильтров. В моей практике это обычно выборки по сервисам; подразделениям и конфигурационным единицам.
Следующим шагом рассмотрим реализацию в SCSM управления проблемами. Что такое «проблема». Когда сотрудник компании обращается в службу поддержки, он обычно говорит: «у меня тут проблема…». Не будем их переучивать, но сотрудники ИТ служб обычно используют термин «проблема» для обозначения корневой причины иногда одного, а может быть и нескольких инцидентов. Это необходимо для выявления и устранения не последствий, а первопричин, системных ошибок в инфраструктуре. Именно поэтому лучшей практикой считается разделение разрешения инцидентов, как сбоев у конечных пользователей и проблем: системных ошибок, сбоев или, как их еще называют, «корневых причин».
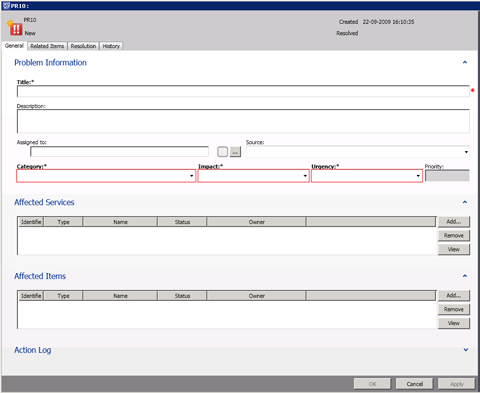 | | Карточка проблемы |
Вызов окна управления проблемами производится также из левой панели. Основная вкладка проблемы очень похожа на аналогичное окно инцидента. В принципе приоритет проблемы определяется аналогично приоритету инцидента: по категории, степени влияния (impact) на бизнес-процессы. Дополнительный фактор, оказывающий влияние на приоритет проблемы: количество и приоритет связанных с ней инцидентов. SCSM содержит функционал для связывания инцидентов и проблем. Это необходимо в нескольких случаях:
для лучшего анализа проблемы и выявления ее причин;
для применения единого обходного пути ко всем инцидентам;
для выявления «слабых мест» в инфраструктуре.
Каждая проблема должна обязательно быть расследована и переведена в статус «известная ошибка» (known error). Это означает, что найдена та самая первопричина ошибки и варианты ее устранения: постоянный и/или временный. Скорость, с которой ошибка должна быть исправлена зависит от приоритета. Например, если с ней связано небольшое количество инцидентов, то решение может быть отложено. Это также отмечается в карточке проблемы. Дополнительным фактором, влияющим на приоритет проблемы становится наличие и приемлемость обходного (временного) решения. Если такое решение есть, и оно устраивает пользователей и ИТ службу, то приоритет проблемы может быть понижен, а в некоторых случаях исправление вообще не производится.
Вся информация о решении проблемы обязательно должна быть внесена на соответствующую вкладку (рис.3). Это необходимо для того, чтобы в последующем либо избегать подобных ошибок, либо устранять их максимально быстро.
Управление инцидентами и проблемами – это всегда самый первый шаг в выстраивании ИТ менеджмента в компании. По статистике IDC 95% компаний в мире начинают внедрение ИТ менеджмента именно с организации службы поддержки (helpdesk) и внедрения описанных процессов. Microsoft System Center Service Manager позволяет грамотно организовать работу ИТ службы, интегрировать работу со всеми остальными приложениями, внедрить учет и контроль работы ИТ сотрудников. В следующей статье мы расскажем о томи, как, используя SCSM, организовать плановое внедрение обновлений и управление знаниями об ИТ инфраструктуре предприятия.
|