Вспомнить все! Компьютер в помощь переводчику. Часть 1Автор: Максим Тигулев
Опубликовано: 09.12.2010
Источник: SoftKey.info Недавно нашел у Александра Чижова Cooler любопытный пример работы переводчика Google - фразу "Он ехал на желтой калине" Google перевел как "He was driving a yellow Mazda" cсылка. Почему же так получается? Ведь на первый взгляд выполнить перевод так просто, тем более на компьютере: надо составить базу взаимных соответствий слов и заменить одно на другое. Первые программы-переводчики так и делали, и результат их работы послужил основой для множества анекдотов и историй, классический пример - перевод инструкции к мыши "Гуртовщики мыши". Давайте разберемся, что нового появилось с тех пор в современных системах компьютерного перевода и как улучшить качество их работы.
Немного истории
Идея машинного перевода (machine translation - MT) как область прикладной лингвистики возникла в 50-х годах XX века практически с появлением первых вычислительных машин. В 1954 году Джорджтаунский университет (Georgetown University) и IBM провели эксперимент по переводу с русского языка на английский язык более шестидесяти предложений. Эксперимент имел огромный успех, его авторы заявляли, что вопрос машинного перевода будет полностью решен в течение ближайших 3-5 лет. После этого было открыто несколько глобальных проектов по созданию систем перевода для разных языков. Но результаты работы создаваемых систем хоть и радовали компьютерных гиков, зато очень огорчали инвесторов, потому как рабочей системы так и не было создано. В результате в 1967 году специально созданная комиссия Национальной академии наук США объявила машинный перевод неперспективным и не заслуживающим финансирования (мне это чем-то напомнило объявление кибернетики лженаукой). И только в начале 80-х годов, когда значительно возросла вычислительная мощность компьютеров, исследования в этой области возобновились.
Три условия хорошего перевода
Что же нужно для хорошего перевода? С первого взгляда все очевидно: большой словарь, чем больше - тем лучше; дополняем словарь устойчивыми словосочетаниями, такими как See you tomorrow - "До завтра", а также прописываем грамматические правила вроде согласования времен, например: "I see" - "Я вижу", "I saw" - "Я видел", "I have seen" - "Я увидел". Вот, собственно, и все.
На практике именно эти задачи и являются основными, однако способы их решения не так просты. С созданием больших баз данных проблем нет, но для перевода, в отличие от словаря, гораздо важнее не накопить, а правильно структурировать информацию. Если внимательнее рассмотреть грамматику русского языка, станет понятно, что существительные изменяются по падежам и по числам, так, что для одного существительного могут существовать до 12 разных форм, а для глаголов и прилагательных - более 30 форм. Следовательно, чтобы переводить предложения, содержащие слова в разных формах, нужно иметь для каждого слова способ соотнесения словарной статьи из словаря с соответствующей словоформой из текста. Поэтому для описания и входного, и выходного языков в системе нужно составить и описать формальную морфологическую модель, на которой будет основываться выбор слова из словаря. Так что создание систем хорошего машинного перевода представляет собой непростую, наукоемкую задачу.
Электронные помощники переводчика
К практической реализации машинного перевода мы еще вернемся, а пока посмотрим на задачу с другой стороны. Пока одни программисты пытались решить в общем виде задачу машинного перевода, другие программисты искали пути облегчения работы человека-переводчика. Так появился широкий класс систем, получивших название "системы помощи переводу" (computer assisted translation - CAT). Как понятно из названия, назначение таких систем - в оказании помощи переводчику, к ним можно отнести: словарь с быстрым доступом (например, по горячей клавише или при наведении на слово курсора мыши), средства проверки орфографии и грамматики, словари специальных терминов, пользовательские словари. Сюда же можно отнести и так называемые конкордансы - очень сложные в составлении алфавитные перечни слов, встречающихся в какой-либо книге или у какого-либо автора, с указанием контекстов их употребления. К системам помощи переводчику также относятся и системы памяти переводов (translation memory - ТМ), которые мы и рассмотрим далее.
Но прежде - небольшое лирическое отступление. Лет десять назад я работал в одном небольшом банке, где мне приходилось переводить с английского языка счета, регулярно поступавшие от иностранного партнера. Документы были однотипные и содержали большое количество строк платежных позиций, от документа к документу менялось их количество, иногда появлялись новые позиции. Чтобы облегчить себе задачу, я сделал в Word документ - таблицу платежных позиций и их переводов на русский язык. После чего написал небольшой макрос, который брал строчку из очередного счета, искал ее по справочнику и заменял английское название русским.
Так вот этот справочный документ Word и являлся базой данных памяти переводов и вместе с макросом составлял простейшую систему TM. Таким образом, память переводов - это система хранения уже переведенных фрагментов текста и последующего поиска по ним. Прежде чем использовать такую систему, ее надо "обучить", то есть накопить начальную базу вручную либо с помощью корпуса параллельных текстов - так лингвисты называют оригинальные тексты и сделанные к ним переводы. Минимальной единицей памяти перевода является сегмент, обычно одно предложение, но сегменты могут быть и более длинными. При автоматическом накоплении памяти переводов программа сама разбивает параллельные тексты на сегменты, затем производит их выравнивание, то есть подбор соответствия оригинального сегмента переведенному. Пары оригинал - перевод сохраняются в базе, а также могут быть выгружены в файл стандартного формата TMX. Благодаря стандартизации единожды созданные базы могут быть использованы в разных CAT-программах.
"А теперь запомните правильный перевод". Программа OmegaT
Рассмотрим одну из программ для помощи переводчику, она называется OmegaT и распространяется свободно. Программа представляет собой не совсем обычный текстовый редактор, поэтому перед работой с ней настоятельно рекомендуется прочитать инструкцию.
Рабочей единицей перевода в программе является "Проект". Перед выполнением перевода "Проект" необходимо создать (пункт меню "Проект/Создать"). Далее необходимо указать в поле "Имя файла" название будущего проекта (это будет название каталога, в котором будут храниться все базы и файлы) и нажать кнопку "Сохранить". Программа покажет диалоговое окно создания проекта (скриншот ниже).
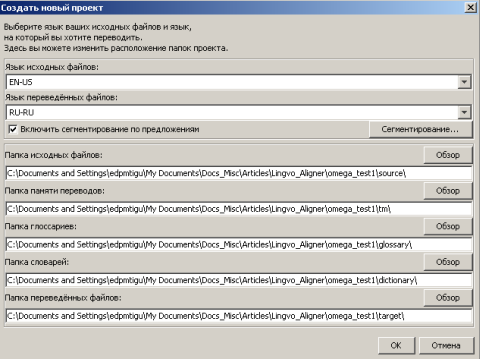
В этом окне можно проверить направления перевода и расположения файлов "Проекта". По умолчанию все настройки верные, поэтому просто нажимаем кнопку "ОК". Программа создаст необходимые файловые структуры. Но так как проект новый, то файлов исходных текстов в нем нет, поэтому программа покажет диалоговое окно "Файлы проекта".
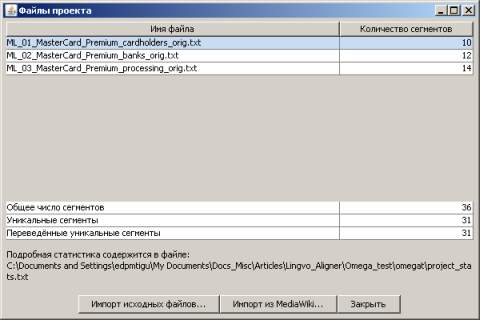
Добавим в проект файлы, нажав кнопку "Импорт исходных файлов". После добавления всех файлов выберем в окне "Файлы проекта" первый документ и нажмем кнопку "Закрыть".
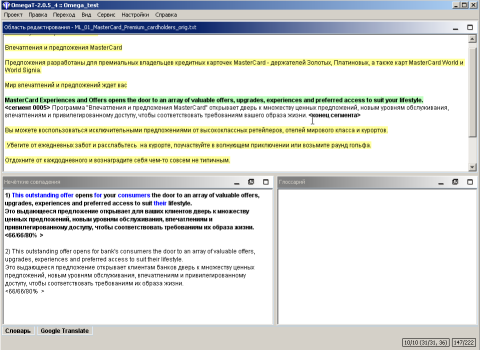
При открытии файла программа проводит сегментацию исходного текста и показывает нам первый сегмент, при этом оригинальный текст будет выделен зеленым цветом. Переводим текст, вводим перевод вручную между символами границ сегмента (в угловых скобках) и нажимаем клавишу Enter. Что происходит далее? Программа сохраняет первый сегмент и его перевод в базе данных памяти переводов и переходит ко второму сегменту. Если содержимое следующего сегмента в точности соответствует тому, что уже есть в памяти переводов, то программа сразу подставит перевод между символами в поле. Нам останется только подтвердить перевод нажатием клавиши Enter. Если в памяти переводов найдено нечто похожее (с заданной вероятностью) на оригинальный текст, то программа покажет в окне "Нечеткие совпадения" несколько близких вариантов, которые переводчик может вставить в текст и исправить при необходимости. Новый вариант также будет добавлен в память перевода. После завершения перевода всех файлов по сегментам сформируем конечный результат (меню "Проект/Создать переведенные документы"),
результаты будут сохранены в выходном каталоге, а "обученная" база памяти переводов будет доступна для дальнейшего использования.
Легко заметить, что система памяти перевода эффективно работает при двух условиях: есть большой корпус параллельных текстов - чтобы создать качественную базу памяти переводов; переводчик работает с похожими текстами, в противном случае совпадений не будет и применение технологии будет бесполезным. Так, в приведенном выше примере со счетами перевод был бы просто идеальным и почти полностью автоматическим. Также эта техника годится при переводе публикуемой отчетности компаний (переводятся типовые фразы), для перевода текстов договоров и соглашений (юридические документы являются строгими, в них повторяются даже целые разделы), а вот для перевода художественной литературы технология памяти переводов вряд ли подойдет.
В следующей части мы рассмотрим универсальную систему машинного перевода PROMT LSP 9.0, ее возможности по переводу текстов, а также способы улучшения качества и точности перевода. Также мы найдем ответ на загадку переводчика Google.
|