InData 2.0: верстка каталогов в InDesign.Автор: Виктор Деревянко
Опубликовано: 14.08.2009
Источник: SoftKey.info  Не так давно мы уже рассматривали проблему автоматизации верстки в InDesign (с помощью программы EasyCatalog). Программа отличная, мощная, но и цена у нее достаточно высока. А если такой мощный набор функций не нужен? Нет ли чего попроще и подешевле? Не так давно мы уже рассматривали проблему автоматизации верстки в InDesign (с помощью программы EasyCatalog). Программа отличная, мощная, но и цена у нее достаточно высока. А если такой мощный набор функций не нужен? Нет ли чего попроще и подешевле?
Есть. Плагин InData 2.0, разработанный компанией Em Software. Его будет вполне достаточно для автоматизации верстки прайс-листов, каталогов, расписаний разнообразных списков и справочников - любых повторяющихся данных.
Сразу скажу, чего в InData нет. Нет двунаправленной связи между исходными и сверстанными данными. Нет возможности импортировать данные из базы данных через ODBC или любые другие интерфейсы. Нет сложного интерфейса, позволяющего визуально задать иерархию верстаемых данных. Тем не менее, плагин способен очень и очень на многое.
Принцип работы плагина прост. Предположим, вам требуется сверстать некий набор повторяющихся данных, например, список сотрудников. Вы подготавливаете исходные данные в виде CSV-файла, в котором каждой строке соответствует отдельной записи списка. Далее, вы создаете новый текстовый фрейм в документе InDesign и размещаете в нем так называемый прототип. Прототип - это программа на языке прототипирования InDesign. В простейшем случае прототип задает внешний вид сверстанной записи, т.е. служит образцом. Например, вы хотите чтобы ФИО сотрудника были выделены курсивом, а телефон помещался в конце строки. Нет проблем. Вы подготавливаете такой прототип исключительно средствами InDesign - ФИО выделяете курсивом, между ФИО и телефоном ставите символ табуляции, смещающий последующий текст до конца строки. Единственный нюанс - вместо реальных ФИО и телефона вы пишете названия полей - "surname", "name", "phone" и т.д. Названия полей могут быть любыми. Вы сами определяете их в первой, служебной строке прототипа. Итоговый, прототип выглядит примерно так:
 | | Пример простейшего прототипа InData |
Теперь, чтобы выполнить верстку, нужно дать команду InData импортировать данные из указанного файла. InData считает из исходного файла все записи, строка за строкой, и каждую оформит в соответствии с прототипом. На место "surname", "name", "phone" будут подставлены фамилии, имена и телефоны. Вы сверстали одну запись, плагин сверстал все остальные - по образцу.
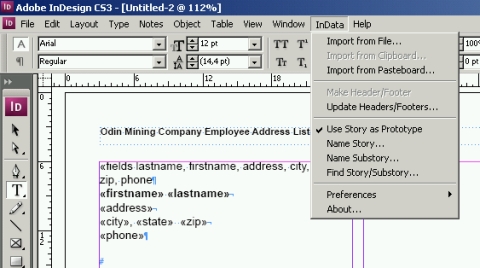 | | Меню и образец прототипа InData |
Как я уже сказал, в простейшем случае прототип задает внешний вид сверстанной записи. Но этим его возможности не исчерпываются. С помощью прототипа можно задавать логику верстки, создавать иерархию верстаемых данных, размещать картинки, формировать таблицы и колонтитулы. Язык прототипирования очень мощный. Правда без навыков программирования, при работе с ним, не обойтись.
Подготовка прототипов
Прототипы InData могут размещаться практически в любых текстовых фреймах документа. Чаще всего их размещают на первой странице или на рабочем поле ("pasterboard"). Единственное исключение - их нельзя размещать на мастер-странице.
Первая линия прототипа задает структуру строки данных в исходном файле. Она начинается с ключевого слова "fields", за которым следует список полей через запятую. Заданные в первой строке имена полей используются затем для их идентификации. Остальные строки прототипа задают порядок размещения и оформления данных для каждой записи из файла. Имена полей, заключенные в шевроны, указывают места, куда должны быть вставлены реальные импортируемые данные.
Язык прототипирования весьма мощный. Он поддерживает условные выражения, циклы, переменные. Есть возможность запрашивать данные у пользователя и неплохой набор функций для работы со строками. Поддерживается работа с субполями - полями, содержащими более одного выражения.
Условный выражения особенно востребованы. Типичный пример использования - исключение пустых строк. Например, при создании списка сотрудников для каждого сотрудника выводятся название, адрес и телефон. Если в списке встретится сотрудник без телефона, то при верстке списка на месте телефона появится нежелательная пустая строка. Добавление в прототип конструкции вида " " решает эту проблему. С помощью условных выражений можно строить иерархии данных. Например, разделить список сотрудников по отделам: напечатать название отдела, затем список сотрудников этого отдела, затем название следующего отдела и т.д. Можно выполнять заданные действия перед или после каждой записи. Скажем, выделить каждую вторую (n-ную) запись цветом фона. Можно сформировать таблицу и проставить в таблице галочки в соответствии с исходными данными. И так далее.
 | | Создание таблицы. Результат и исходный прототип |
Текст прототипа может быть разделен на отдельные текстовые фреймы, связанные между собой. Каждый фрейм содержит логически обособленный кусок программы. В такой структурированной программе ориентироваться гораздо проще.
Создание колонтитулов
InData может автоматически добавлять на страницы верхние и нижние колонтитулы, содержимое которых изменяется от страницы к странице. Например, верхний колонтитул телефонного справочника может содержать фамилии, идущие первыми и последними на странице.
Подобные колонтитулы в InData создаются в несколько шагов. Вначале в текст прототипа включается выражение, помечающее кусок текста, который будет выводиться в колонтитуле. Тексту присваивается однобуквенная метка - A, B, C и т.п.
Далее, в колонтитуле на мастер-странице размещается произвольный текст. Диалог "Make Header/Footer" позволяет связать этот текст с ранее созданной меткой. Вместо текста в колонтитуле будет выводиться либо первое вхождение помеченного текста на странице, либо его последнее вхождение - в зависимости от выбранных настроек диалога.
 | | Создание колонтитулов с помощью InData |
Колонтитулы создаются автоматически, а обновляются вручную. Для обновления предусмотрена отдельная команда в меню InData - "Update Headers/Footers".
Импорт данных
InData поддерживает импорт данных из текстовых файлов с разделителями. Например из CSV-файлов. Любая база данных, любая программа для работы с электронными таблицами позволяет выгрузить данные в таком формате, так что проблем с подготовкой исходных данных быть не должно. Напрямую считывать данные из базы данных или файлов типе Excel плагин не умеет. Правда, умеет импортировать текст из рабочей области страницы и из буферам обмена.
Существует масса различных вариантов текстовых файлов с разделителями. Параметры требуемого формата можно задать в настройках плагина. Плагин позволяет указать разделители между записями, полями и подполями, выбрать набор символов (Macintosh, Windows, Unicode), определить порядок цитирования, задать диапазон импортируемых записей и т.д.
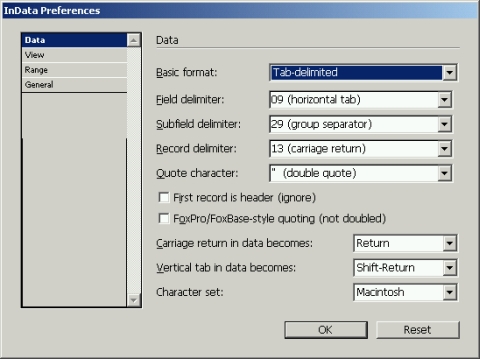 | | Настройки импорта данных |
Загрузка данных в верстаемый документ проводится в два шага. Вначале следует выбрать прототип и указать место в документе, куда должны помещаться сверстанные данные. Затем - выбрать импортируемый файл. Начнется загрузка данных. По умолчанию, в процессе импорта содержимое документа не обновляется. Однако, в настройках можно задать желаемый период обновления - например, каждые 10 секунд. При этом процесс импорта замедлится, но зато станет нагляднее. После завершения импорта InData автоматически формирует верхние и нижние колонтитулы.
Импортированный текст может содержать теги. Поддерживается два варианта таггированого текста - тэги InDesign и тэги Quark XPress (требуется плагин xTags)
Импорт графики
InData умеет работать не только с текстом, но и с графикой. Т.е. умеет верстать картинки. Для того, чтобы сверстать картинку, в прототип необходимо добавить графический фрейм и выражение "set filename of picture n to field", связывающее n-ый графический фрейм с полем, содержащим имя файла с картинкой.
 | | Пример прототипа для верстки текста с картинками и результат верстки |
Загружаемая картинка наследует все свойства пустого графического фрейма: масштабирование, растяжение, смещение и угол наклона картинки внутри фрейма, цвета и тени, отсечение, рамку, поворот картинки и т.д. Значения этих свойств можно изменять двумя путями. Во-первых, в настройках. Заданные в настройках значения будут распространяться на все без исключения импортированные картинки. Во-вторых, с помощью конструкция языка прототипирования. Это более общий способ, позволяющий задать значения любого параметра индивидуально для каждой картинки. Язык прототипирования InData позволяет выполнять импорта PDF файлов, обрезку картинок до требуемых размеров, условный импорт. С помощью языковых конструкций можно указать директорию по умолчанию для всех файлов с картинками, задать картинку, которая должна выводиться в случае, если файл не найден и т.п.
Автоматизация верстки с помощью скриптов
Верстку документов средствами InData можно автоматизировать с помощью скриптовых языков. Под Mac OS это AppleScript, под Windows - VBScript или JScript. InData позволяет присвоить имена каждому используемому "story" (отдельному потоку текста в InDesign) и, в дальнейшем, ссылаться на них в скрипте. Примеры автоматизации верстки с помощью скриптов приведены в документации.
InFlow
Плагин InData поставляется вместе с другим плагином - InFlow, применяемым для автоматического создания новых страниц. Для зарегистрированных пользователей InData плагин InFlow - бесплатен. До тех пор, пока InData работает в демонстрационном режиме, InFlow так же работает в демонстрационном режиме и не позволяет верстать более 10 страниц.
Системные требования
Windows 98/NT/2000/ME/XP/Vista
MacOS 9/X
Adobe InDesign CS2/CS3/CS4 (у Em Software есть аналогичный по возможностям плагин для QuarkXPress - xData).
Конкуренты
Другие продукты Em Software: InCatalog (с двухсторонней связью, поддержкой баз данных и т.д.) , xTags (расширение возможностей таггированного текста, в частности, возможность верстать с его помощью картинки).
Сторонние разработки:
EasyCatalog, PublishNow!, Classified Ad Flowing System и AdImposer.
Выводы
InData позволяет автоматизировать верстку повторяющихся данных в InDesign - каталогов, списков, прайс-листов и т.д. Для того, чтобы выполнить верстку с помощью InData от вас требуется выполнить два действия: подготовить исходные данные в CSV-подобном формате и подготовить прототип сверстанной записи в InDesign. В простейших случаях прототип - это вручную сверстанная запись, в которой вместо реальных данных подставлены имена полей. Однако, язык прототипирования InData очень мощный, с его помощью можно определять весьма нетривиальную логику размещения и форматирования данных. Правда, для этого потребуются некоторые навыки программирования. К счастью, плагин снабжен подробной документацией. Причем первый раздел документации содержит семь пошаговых уроков, снабженных детальными инструкциями и готовыми файлами с примерами. Так что разобраться - вполне реально.
|